research_NLP
語義範疇增強之稠密檢索技術
Enhancing Semantic Representation in Dense Retriever Models
研究背景 Introduction
大型語言模型 (LLMs) 雖然強大,但常面臨「幻覺現象 (Hallucination)」與知識更新困難的挑戰。檢索增強生成 (Retrieval-Augmented Generation, RAG) 技術透過引入外部知識庫來解決此問題,而其中的核心關鍵在於「檢索模組」的精準度。
傳統的關鍵字檢索 (如 BM25) 難以捕捉深層語意;而現有的稠密檢索 (Dense Retrieval) 雖然能進行語意向量匹配,但往往缺乏對細微詞彙語意範疇的理解。本研究旨在透過引入語言學知識結構,強化 Dense Retriever 的語意辨識能力。
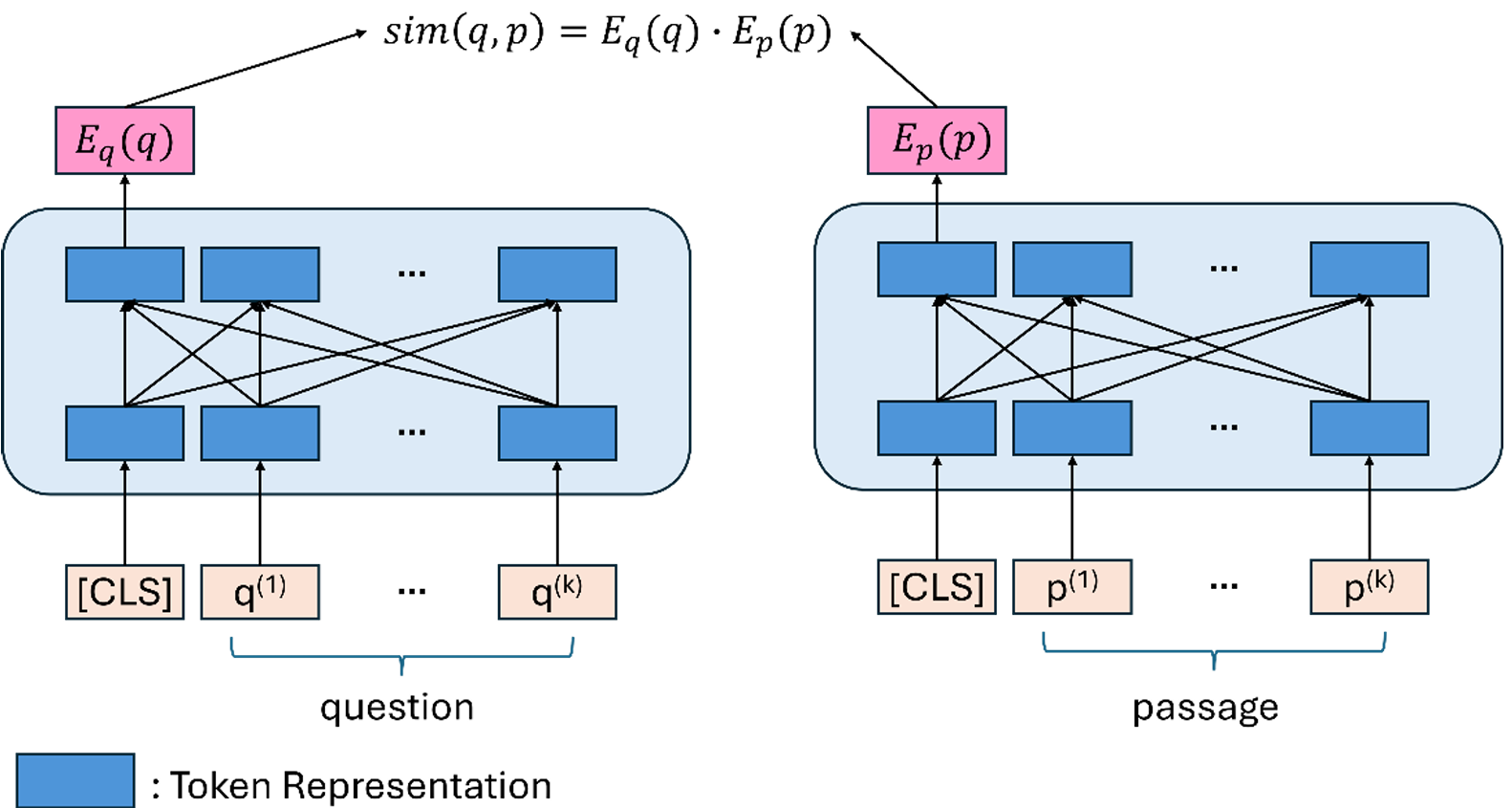
圖 1. Dense Retrieval 常用之 Dual-Encoder 雙編碼器基礎架構
系統架構與方法 Methodology
本研究提出了一種整合「詞彙語意範疇預測」的多任務學習框架。主要技術特點包括:
- 引入《哈工大同義詞詞林》:利用其樹狀結構將詞彙劃分為精細的語意範疇(如:生物、人、物、時間等),作為模型的輔助訓練訊號。
- 多任務學習 (Multi-task Learning):模型同時進行「對比學習 (Contrastive Learning)」以拉近相似語句距離,並進行「詞彙範疇預測」以強化對詞彙意義的理解。
- 模型架構:基於 BERT 的 Encoder,並針對繁體中文語境進行了優化與適配。
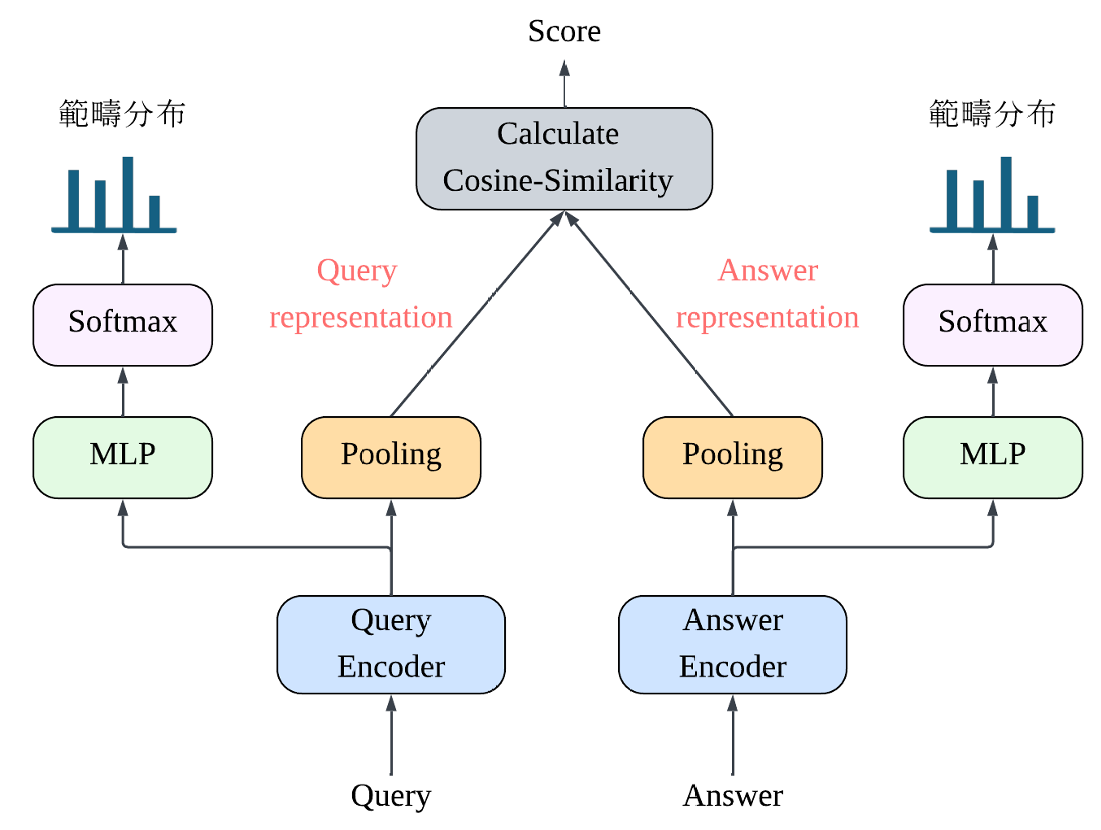
圖 2. 本研究提出之整合語意範疇預測的 Dense Retriever 完整訓練架構
關鍵技術:加權聚合與負樣本採樣 Key Techniques
1. 語意範疇加權 Pooling
傳統使用 CLS token 代表整句語意可能不夠全面。本研究提出了一種基於範疇權重的 Weighted-sum Pooling 機制。模型會自動學習哪些語意範疇(如「實體名詞」可能比「虛詞」重要)在檢索時更具代表性,據此加權生成句子向量。
2. Hard Negative Sampling
為了讓模型學會區分「非常相似但含義不同」的句子,我們在訓練中引入了 Hard Negative Samples(困難負樣本)。透過計算餘弦距離,篩選出那些語意相近但並非正確答案的段落讓模型進行鑑別訓練。
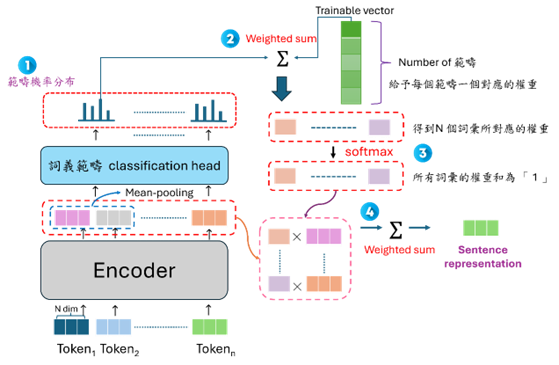
圖 3. 基於詞義範疇權重的 Weighted-sum 句子向量聚合策略
實驗結果與貢獻 Experimental Results
實驗採用了包含 53 萬筆繁體中文學術問答資料集進行驗證。結果顯示:
- 檢索效能提升:引入語意範疇資訊後,模型在 MRR@k 與 Top-k Accuracy 指標上均優於未加入的 Baseline 模型。
- 抗干擾能力:在加入 Hard Negative 的嚴苛訓練條件下,本研究提出的加權聚合方法 (Category Wsum) 表現更為穩定,相較於傳統方法提升約 4%。
- 語意解析度:研究亦探討了詞林不同層級(粗略 vs 精細)對模型的影響,發現資料的覆蓋率與長尾分佈是影響精細範疇學習效果的關鍵因素。
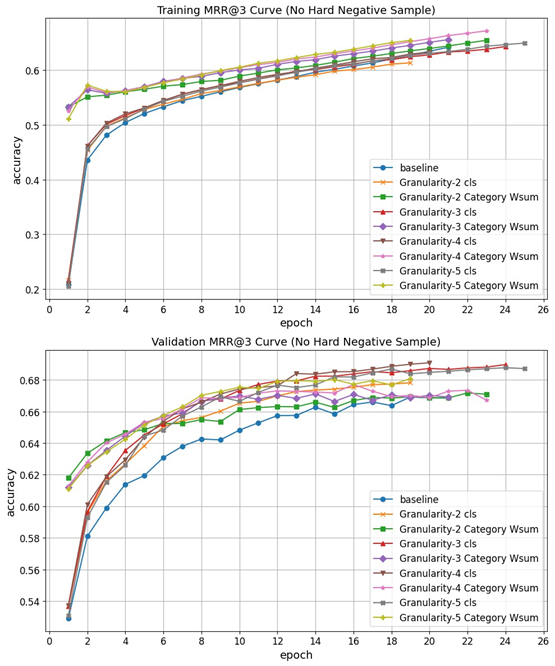
圖 4. 不同訓練策略下的檢索效能 (MRR@3) 比較曲線